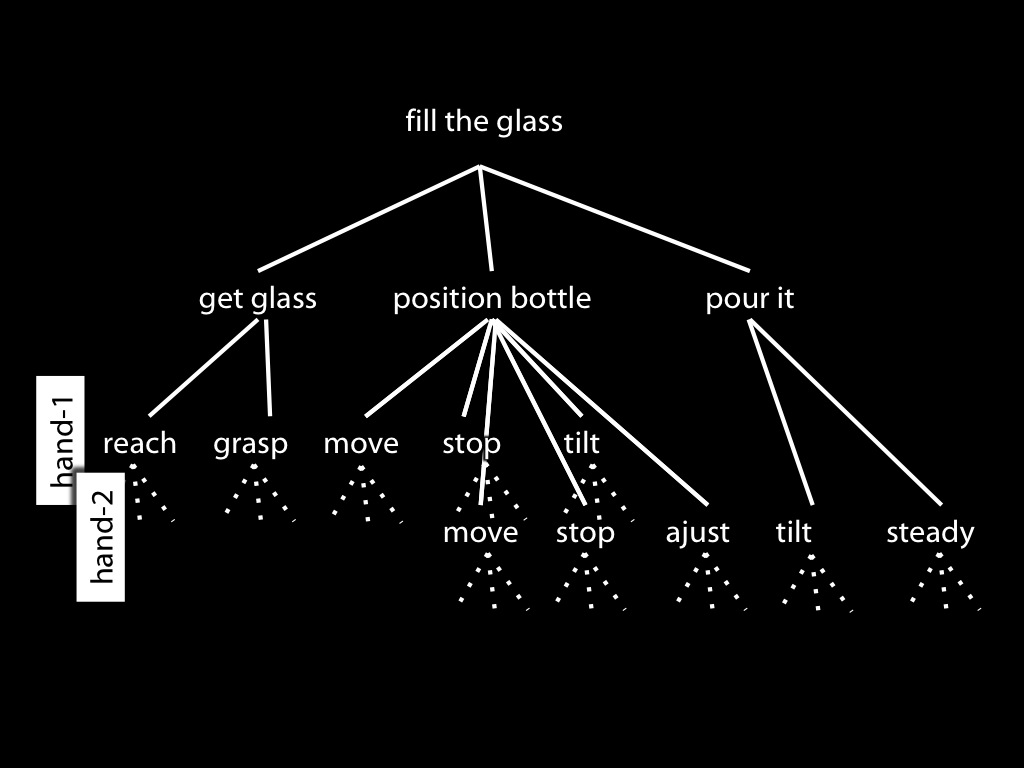
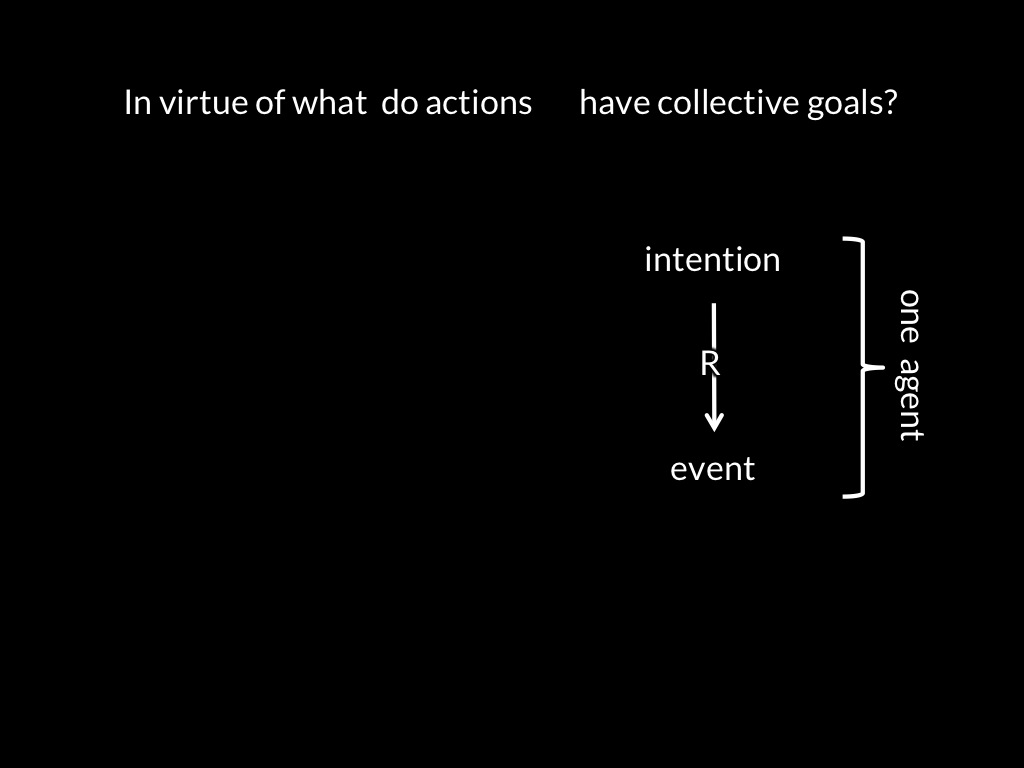
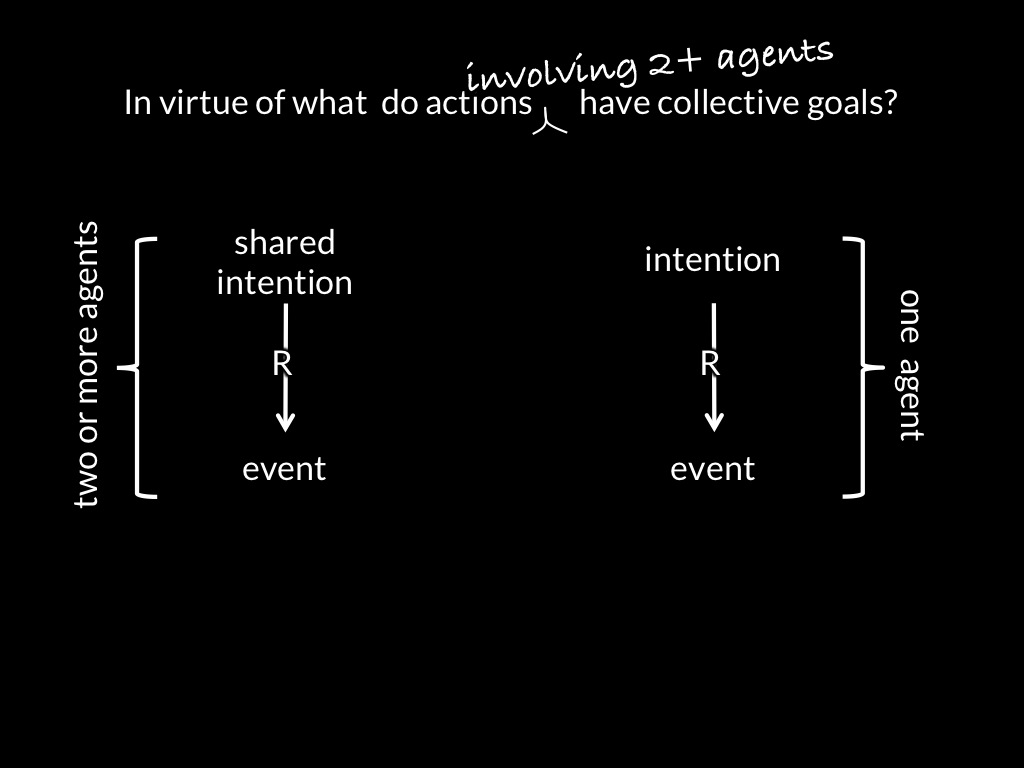
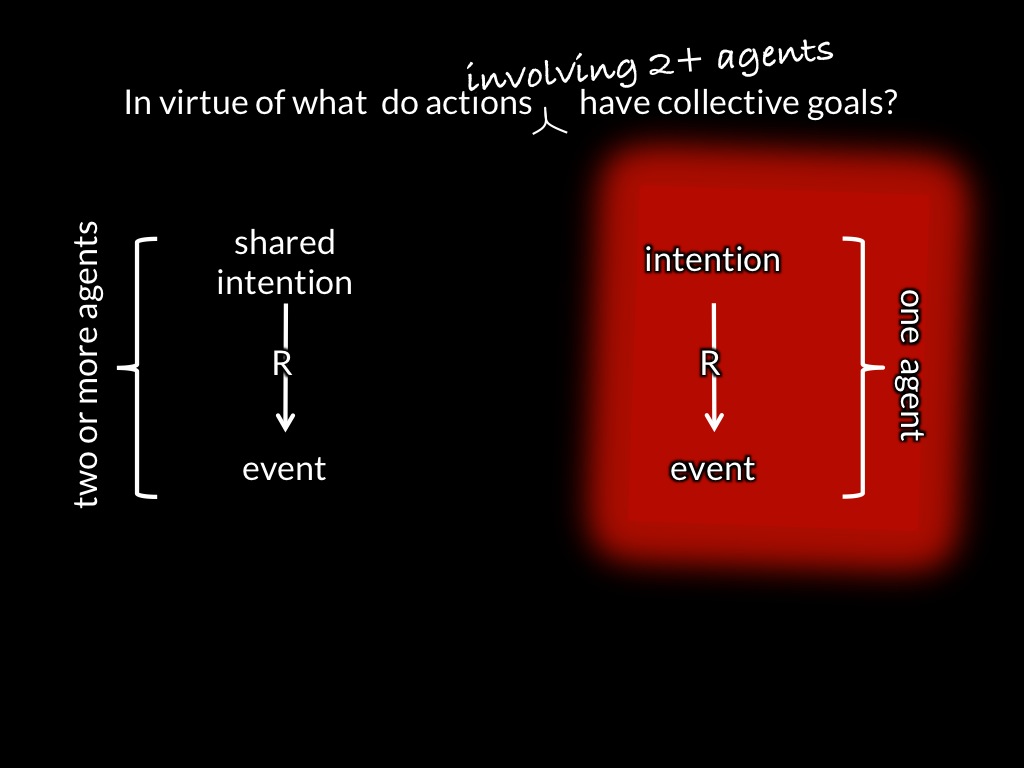
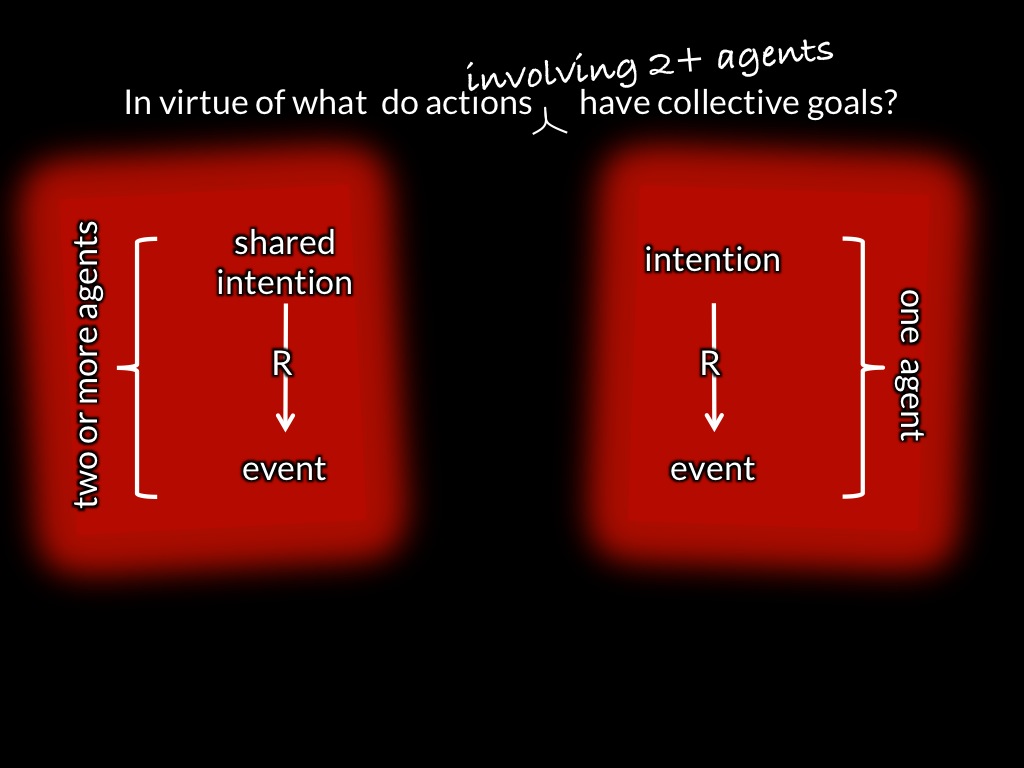
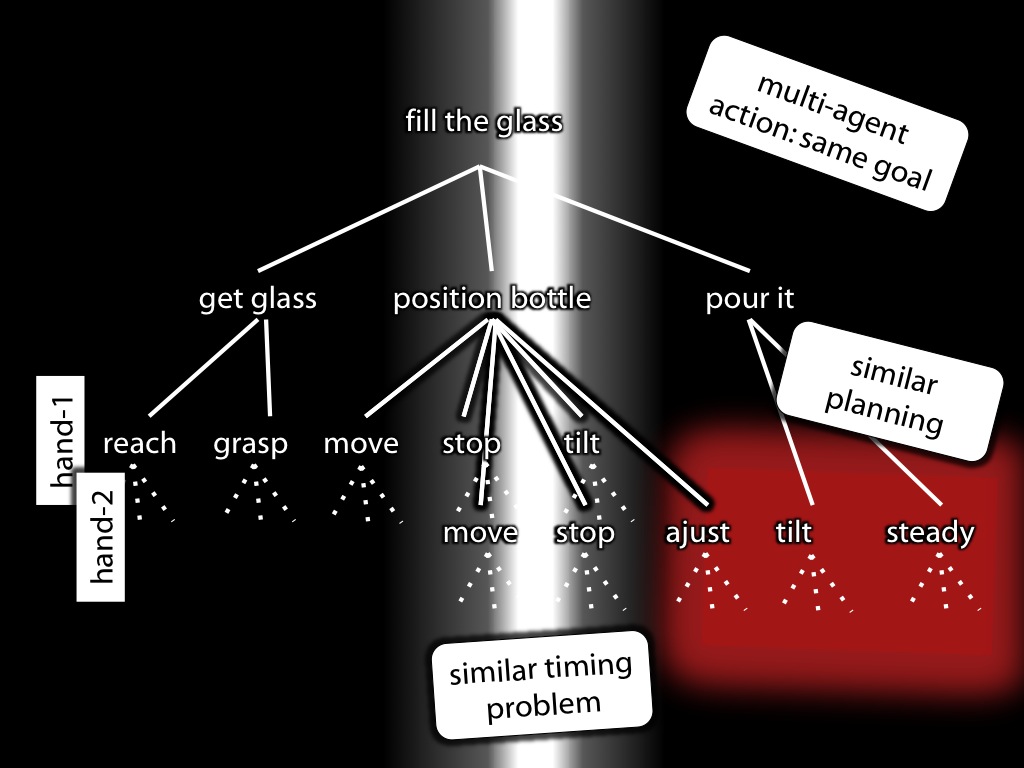
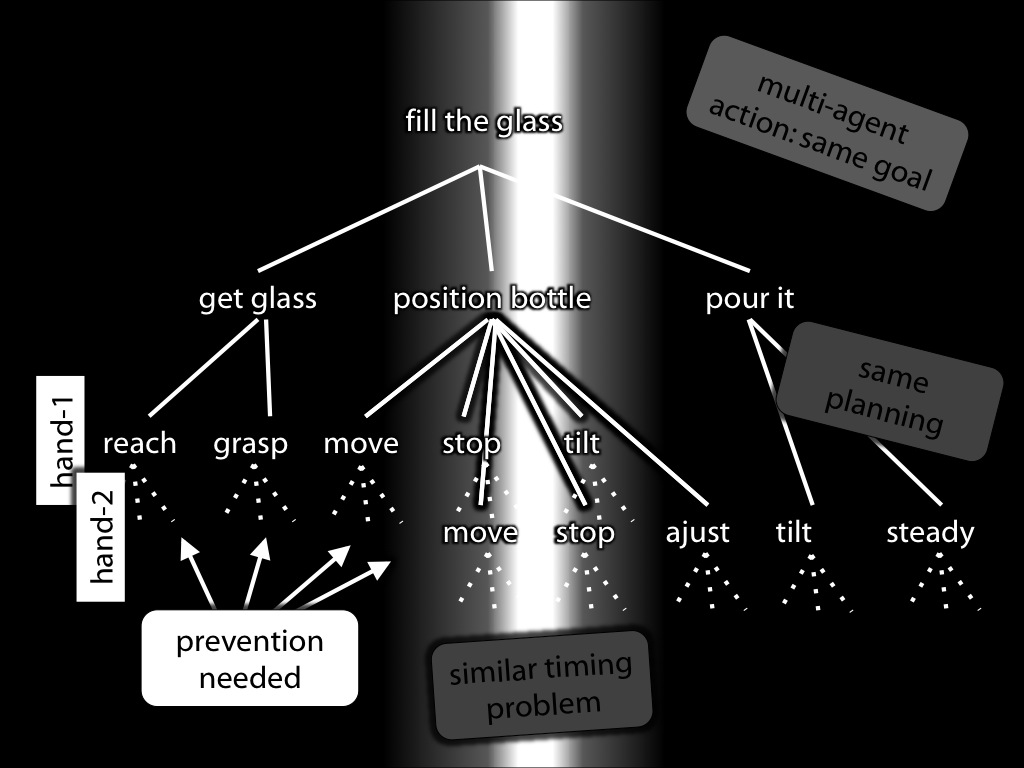
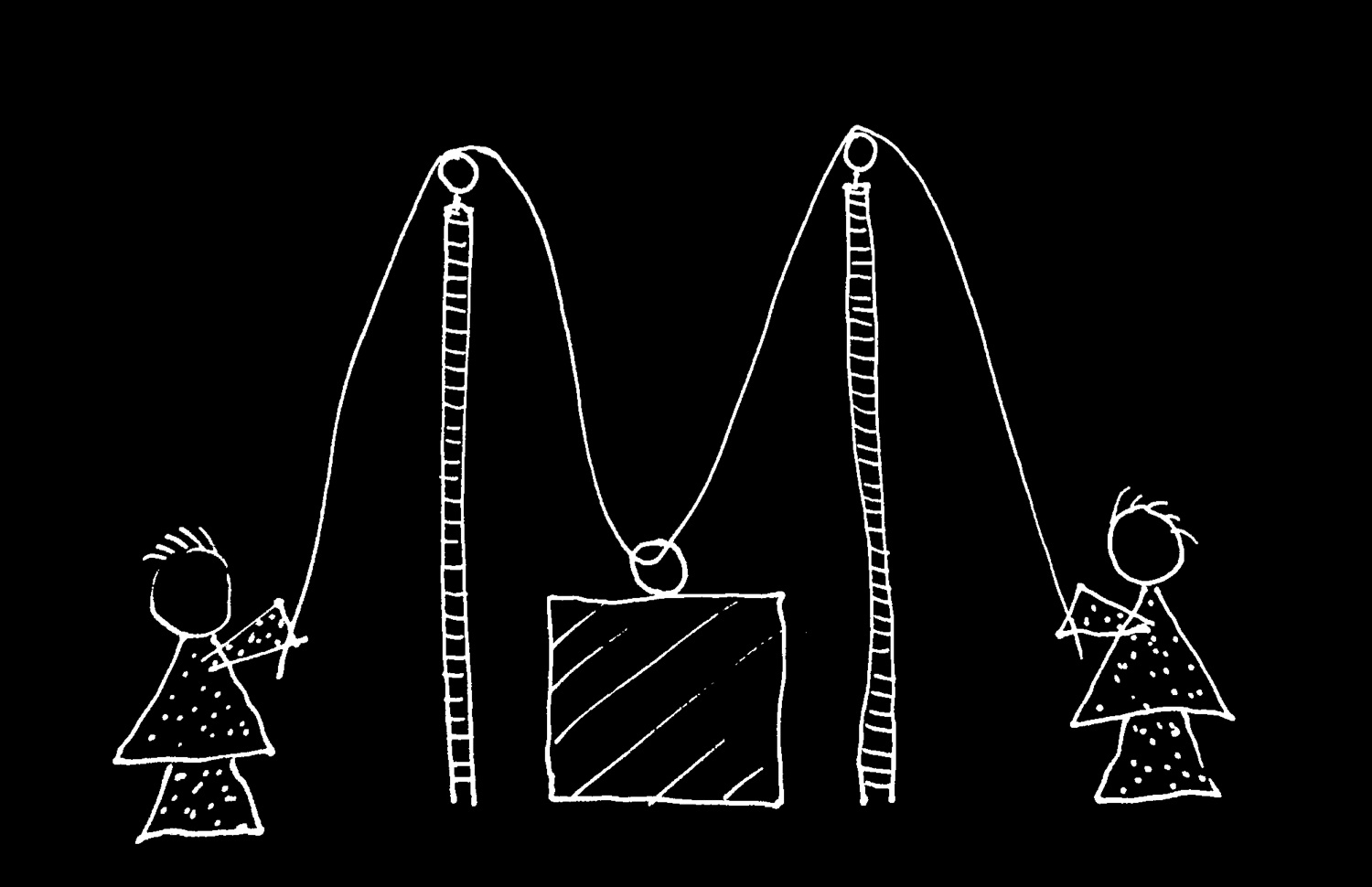
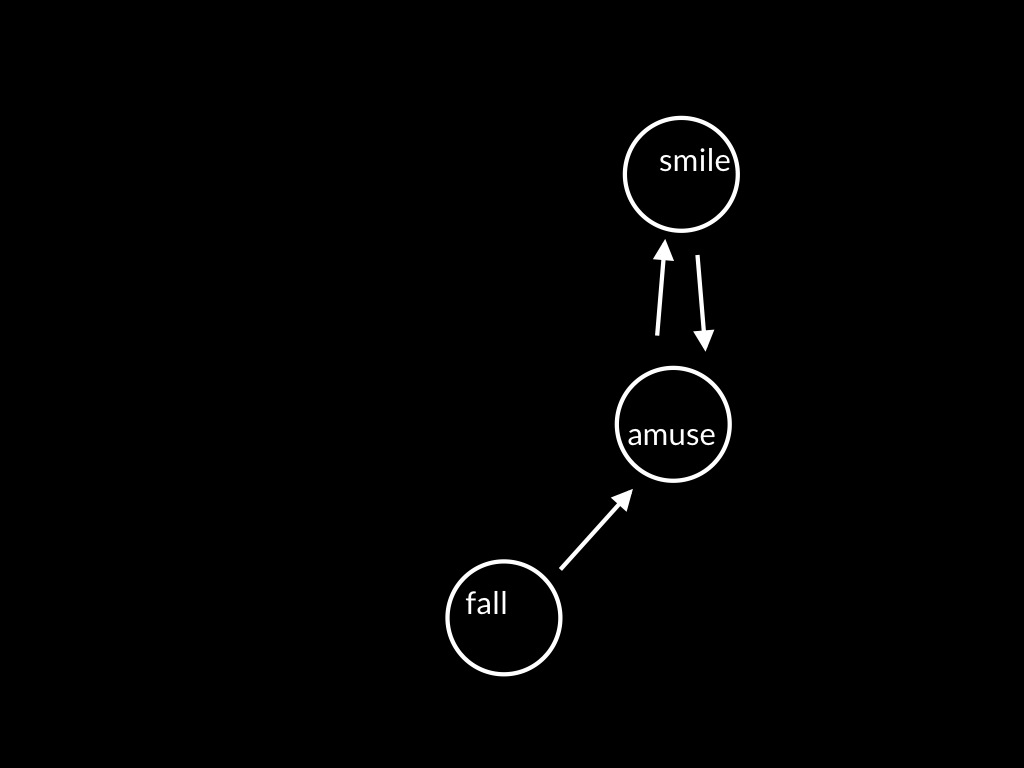
[*todo: remove motor stuff for this talk! Also: don't lose sight of idea that control is a way of knowing.]
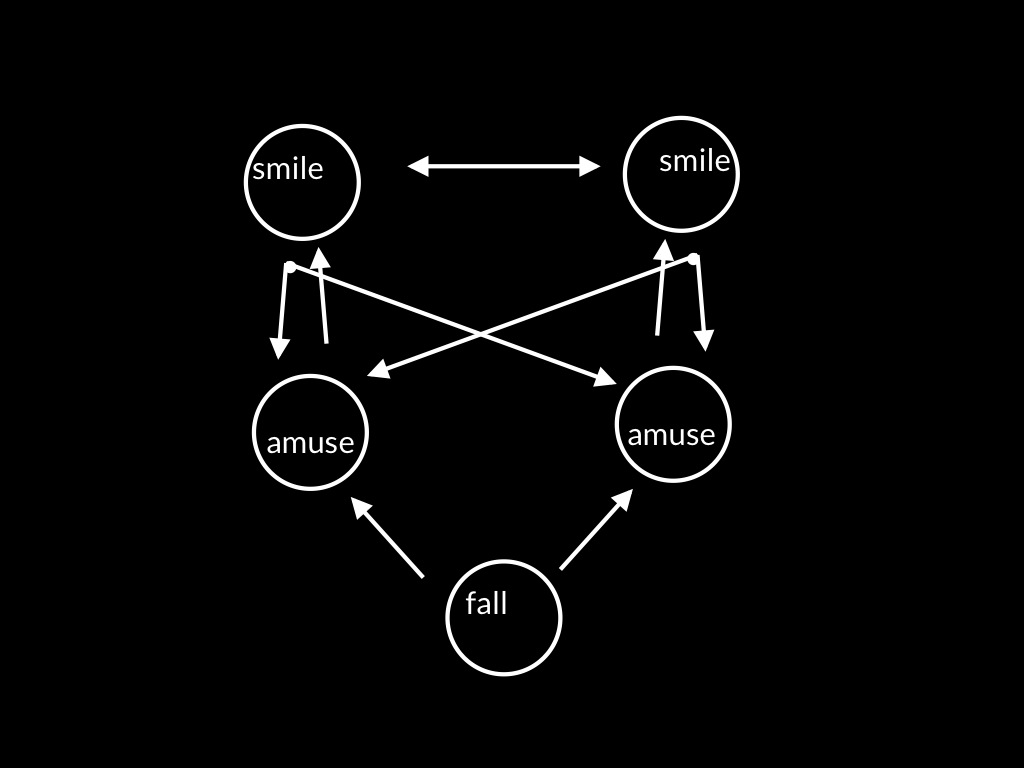
[*todo: need slide with control arrows highlighted (my emotion controls yours).]
[*Structure:
(i) I know because my emotion controls yours;
(ii) But if my emotion controls yours, how can yours be amusement at the clown's falling? because control is partial, and reciprocal;
(iii) But the mere fact of control isn't enough for knowledge; rather, control must show up in experience somehow.
After all, for all I have said so far, we might, in sharing a smile, be unaware that our emotions are locked together.
(iv) There must be an experience that is distinctive of sharing a smile.
(iv) Note that I don’t want to say that someone who is sharing a smile needs to understand the situation in the way I’m describing it.
All I'm claiming is that the fact of reciprocal control somehow affects our awareness.
(v) It may affect in our awareness insofar as we are sensitive to contingencies between our own actions' and others' actions,
and between our actions and the causes of them.
(vi) So my position is this: the reciprocal control justifies each agent in making judgements about how the others' amusement is unfolding,
and this justification is at least indirectly available to the agents by virtue of their having experiences characteristic of sharing a smile.
]
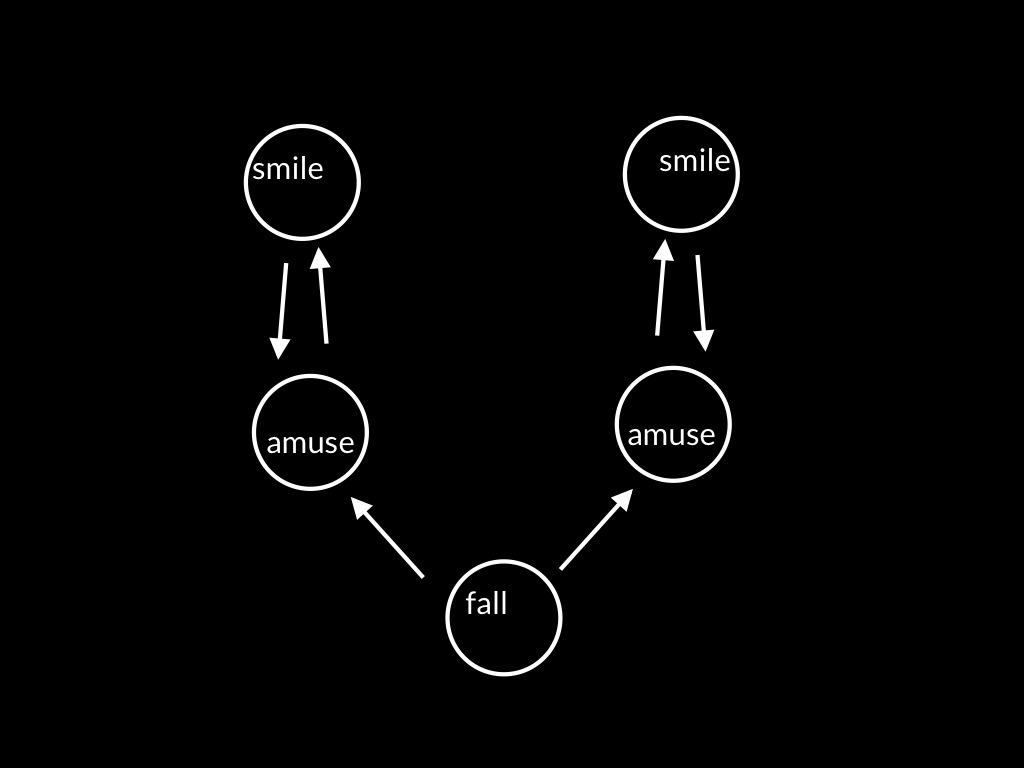
Our being emotionally locked together means that
to a significant extent I am feeling what you are feeling,
that the way my amusement is unfolding matches they way your amusement is unfolding.
So if you know how your own amusement is unfolding and you know that we are emotionally locked together,
you can know much about how my amusement is unfolding.
So joint expressions of emotion like sharing a smile have the potential to enable us to know not just that others are amused but how their amusement is unfolding.
But the fact of reciprocal control (which means our emotions are locked together) together doesn’t all by itself mean that we can know how each other’s emotions are unfolding.
After all, for all I have said so far, we might, in sharing a smile, be unaware that our emotions are locked together.
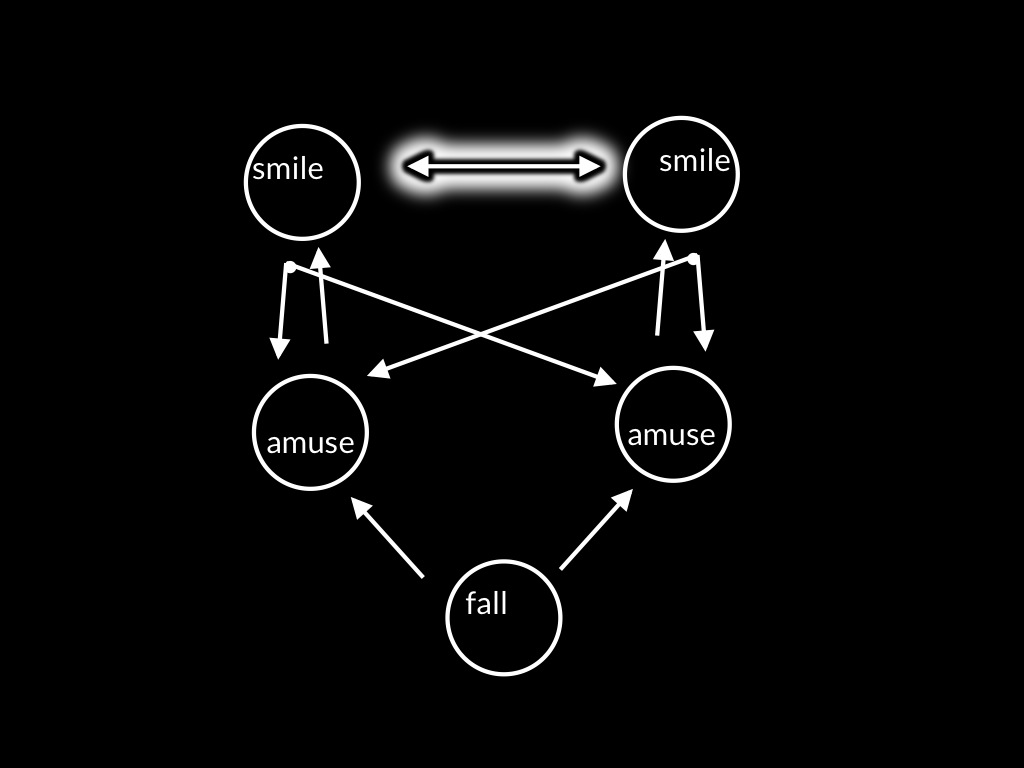
Now you might think this sounds implausible because its hard to imagine sharing a smile without an experience that is distinctive of sharing a smile.
And it might be natural to describe this experience as an experience of sharing.
But even if that is correct, it’s necessary to say exactly why someone who is sharing a smile is in a position to know things about how the other’s emotion is unfolding.
I don’t want to say that interaction only helps if you know that your emotions are locked together.
That is, I don’t want to say that someone who is sharing a smile needs to understand the situation in the way I’m describing it.
But minimally the fact of reciprocal control must somehow feature in our awareness.
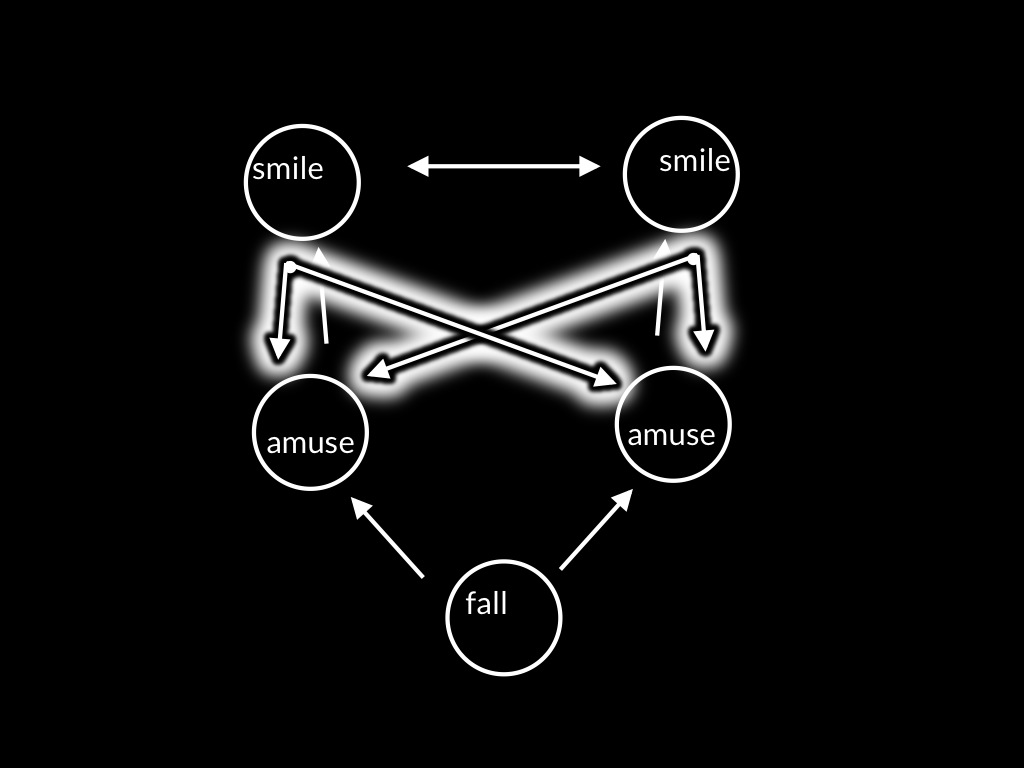
[*The idea in outline:
\begin{enumerate}
\item the ways our amusements unfold is locked together
\item this is in part because a single motor plan has two functions, production of your smile and prediction of my smile
\item the single motor process means that we might experience being locked together in some way (not that our emotions are locked together but that our actions are, in something like (but not exactly) we experience actions when seeing ourselves in a mirror or on CCTV (check Johannes’ discussion of this)).
\end{enumerate}
]
Here I want to offer a wild conjecture.
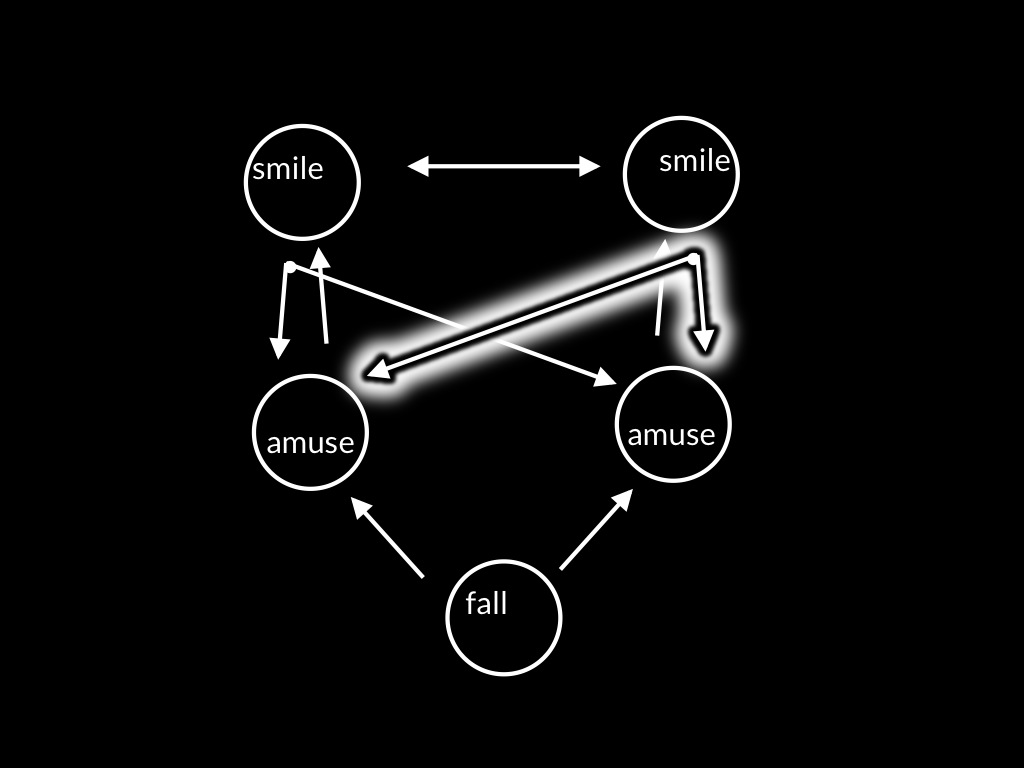
In joint expressions of emotion there is a single motor plan with two functions,
production and prediction.
The motor plan both produces your own smile and enables you to predict the way the other’s smile will unfold.
[*missing step about monitoring and experience. (The Haggard idea: motor planning can give rise to experiences concerning one's own actions \citep{Haggard:2005sc}.)]
Because your plan has this dual function, your experience of the other’s (my?) smile is special.
From your point of view, it is almost as if the other is smiling your smile.%
\footnote{
Joel caricatured this idea seeing me eating fruit: ‘it’s almost as if I’m eating that fruit.’
}
This means that sharing a smile has characteristic phenomenology.
This odd phenomenological effect means that in sharing a smile we can each think of the situation almost as if there were a single smile.
And almost as if there were a single state of amusement.
(In thinking of the situation like this it is important that we have a subject-neutral conception of the amusement and an agent-neutral conception of the smile.%
\footnote{
Tom Smith asked about this. I clarified that I wasn’t suggesting there was a state of amusement which is ours, nor that the subjects are thinking of the situation in this way.
That’s the point of the appeal to subject-neutral amusement.
It’s a partial model of the situation.
}
[*Here I think I’m shifting back from the perspective of the participants in sharing a smile to the perspective of the theorist.
Probably what I should say is, first, that a theorist can think of the situation in this way and use this to argue, second, that there is a simple, partial conception of the situation that doesn’t require understanding reciprocal control and interlocking emotions but is sufficient for each smiler to have knowledge of the way the other’s emotion unfolds.]
So my suggestion is that in sharing a smile you experience my smile almost as if it were yours (or: you experience me almost as if I were smiling your smile),
and so you might also experience our situation almost as if it involved a single state of amusement.
It's more like we each plan a single smile.
But---to reply to the objection---these plans have a dual function.
Your plan both produces your own smile and enables you to simulate---to experience---my smile.
And likewise for my plan.
The interdependence of our smilings means that we could each think of the situation as if it were one in which a single state of amusement were responsible for our actions.